Solving On-demand Delivery from First Principles (Part 1)

In simple terms, On-demand delivery involves getting a product or service to a user ASAP. This is the model employed by every app that delivers food, ride hailing services, or ecommerce purchases.
In today’s world of AI, potential founders in this space lack the fundamental knowledge to go from 0 to 1 and end up building prototypes that fail to work as intended, or don’t scale. This article develops the basic concepts you should account for in your product design before building; including some foundational mathematical modeling work that is required to optimize product and service recommendations for users.
How does it work?
There are a lot of successful companies in this space: Uber, Glovo, DoorDash, etc. and they all approach this problem differently depending on their exact business model and product, but there are certain general patterns for building systems like this and we will look at some of them in this article.
Building Blocks: Essential Models
On-demand services essentially operate a marketplace that connects users to the products and sevices they need. Solving the user’s need here primarily involves optimizing for service quality; where service quality includes factors such as timeliness, price/budget matching, as well as overall product/service satisfaction (accuracy).

As we can see from the image above, the platform solves two problems:
- A search problem for the user; and
- An aggregation problem for product or service (POS) providers
This article will focus on the search (user) side, while an upcoming one will look at the POS provider aggregation.
POS Search
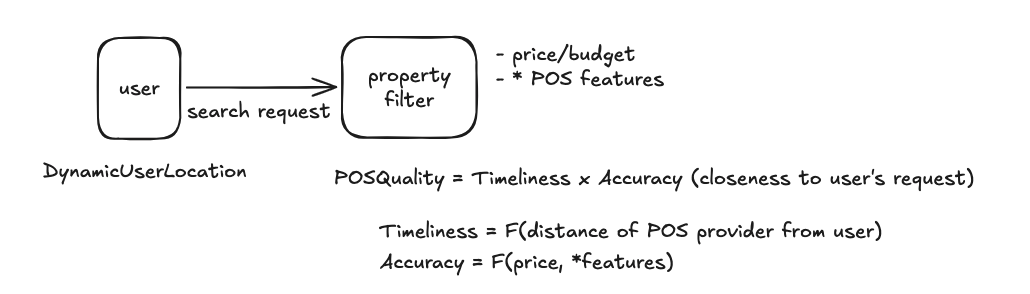
We can see that the user’s search problem has two principal components: timeliness and accuracy.
Timeliness is a function of the distance from the POS provider (candidate) to the user. Specifically, the Haversine distance.
The closer the provider is to the user, the better in an on-demand scenario. So from a model perspective this will always be an inverse or inverse-squared law.
Accuracy has to do with the match coefficient between what the user has ordered and the available products and services on the platform at the time of placing the order.
Good user recommendations will have both a high timeliness score and a high accuracy score. The product of these two scores is called POS Quality.
POS Quality Scoring (Search Results)
Each user search returns a list of ranked results. These results are typically sorted in descending order of quality score with the highest quality matches near the top.
Below I have listed out the mathematics that builds up the quality score from first principles. I will explain each step and also link to code examples on Github so you can use this in your projects as well.

The first lemma defines our quality model as the product of the timeliness score (a score representing how quickly the product or service can be delivered to the user) and the accuracy score (a score representing how close the offered product or service is to the user’s order).
The other lemmas go on to define each component of the quality score (QS) as follows:
Second lemma expresses the timeliness score as the ratio of the timeliness weight (Github) to the Haversine Distance (Github)
The Third lemma discusses the fact that POS features can either be thought of as quantitative (numerical, ratio-based comparison), categorical (text, boolean comparison) or flavor (multiple choice). For the models we have developed on Github, we have only treated quantitative and categorical features.
The fourth lemma provides an expression for the accuracy score (which represents the closeness of each provider’s offer to a user’s order) based on the laws of logarithms. It features a product of the respective sums of the quantitative and categorical distributions of user/provider feature pairs (Github). Also featured is the accuracy weight (Github)
The fifth and sixth lemmas fully develop the quality score as the product of the timeliness score and the accuracy score. You can see the full Python implementation of the quality score on Github.
Use Case (Example)
Also available on Github, and based on the Python implementation of the quality score in that repo.
def test_quality_score():
user_location = lagos_lat, lagos_long
provider_location = abuja_lat, abuja_long
user_price_preference = 30
user_provider_rating_preference = 4.8
user_crust_preference = "regular"
user_item_type = "pizza:mozzarella"
user_search_parameters = (
[user_price_preference, user_provider_rating_preference],
[user_crust_preference, user_item_type],
)
provider_1_price = 32.50
provider_1_rating = 4.6
provider_1_crust = "thick"
provider_1_item_type = "pizza:mozzarella"
provider_2_price = 31.20
provider_2_rating = 4.7
provider_2_crust = "regular"
provider_2_item_type = "pizza:mozzarella"
provider_1_parameters = (
[provider_1_price, provider_1_rating],
[provider_1_crust, provider_1_item_type],
)
provider_2_parameters = (
[provider_2_price, provider_2_rating],
[provider_2_crust, provider_2_item_type],
)
qs_provider_1 = quality_score(
user_location,
provider_location,
user_search_parameters,
provider_1_parameters,
)
qs_provider_2 = quality_score(
user_location,
provider_location,
user_search_parameters,
provider_2_parameters,
)
assert qs_provider_1 == 0.0001378627126888822
assert qs_provider_2 == 0.0002836274187406838
assert qs_provider_2 > qs_provider_1
In this use case, we have a user “Bob” who wants to order pizza. Bob is in a certain location while we have two providers that are both in a location that is different from Bob’s location.
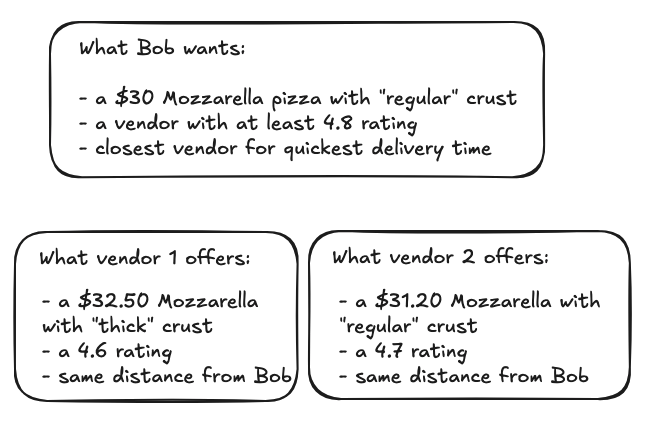
Which vendor is recommended?
As we can see from the image above, the price offered by Vendor 1 is much higher than Bob’s budget; also it has the wrong crust type and a much lower rating than what Bob would prefer, so it does not seem like a very good match for Bob’s order.
Vendor 2 on the other hand offers Bob’s desired pizza at a much closer price and in the correct crust type, with a much closer rating to what Bob would prefer.
We also see that both Vendor 2 and Vendor 1 are the same distance from Bob.
So our simple analysis already shows that Vendor 2 should be a much better recommendation for Bob than Vendor 1, and the code in our use case provides this with our quality score formulation:
we see that the calculated quality score for Vendor 2 is essentially 2x (twice) the calculated quality score for Vendor 1, indicating a much better match
quality scores like this can be used for real-time recommendations in massively parallel distributed scenarios like customer order processing, ride hailing and ecommerce dispatches
Conclusion
In this article (first in a series), we have looked into the customer search side of on-demand delivery services; exploring some basic mathematical modeling that enables founders and engineers to think correctly about how to best match users to providers in real-time within their on-demand marketplaces.